
hashmap底层数据结构
一、HashMap简介
1、它是一个通过Map接口实现的一个双列集合,主要是以键值对的方式进行存储,每一个键值对都有一个键和一个值。
2、每一个键都是唯一的,值可以重复,后面添加的键会覆盖前面相同的键。
3、HashMap存储结构采用的是哈希表的结构,元素的存储顺序不能保存一致,如果键是自定义的对象的话,需要重写hashcode方法与equals方法,才能保证键的唯一。
二、HashMap存储的原理
1、版本区别
jdk8以前:
在jdk1.7中,首先是把元素放在一个个数组里面,后来存放的数据元素越来越多,于是就出现了链表,对于数组中的每一个元素,都可以有一条链表来存储元素。这就是有名的“拉链式”存储方法。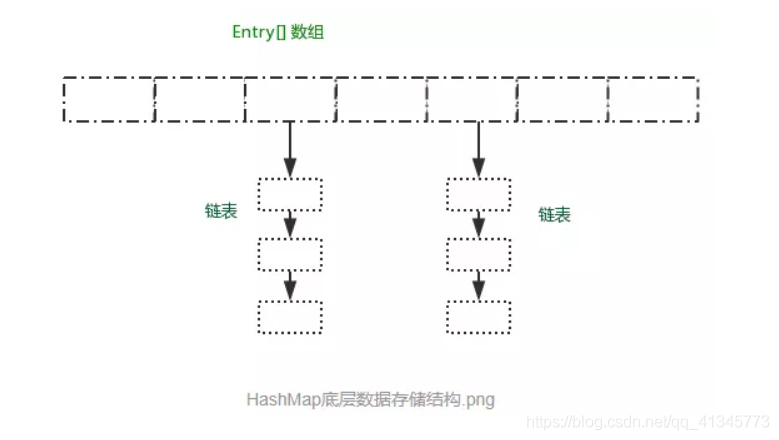
jdk8以后:
由于存储的元素越来越多,链表也越来越长,在查找一个元素时候效率不仅没有提高(链表不适合查找,适合增删),反倒是下降了不少,于是就对这条链表进行了一个改进。如何改进呢?就是把这条链表变成一个适合查找的树形结构,没错就是红黑树。值得注意的是,因为需要为了退化成链表和遍历做准备,这个红黑树并不是纯红黑树,而是红黑树和双向链表的叠加结构。
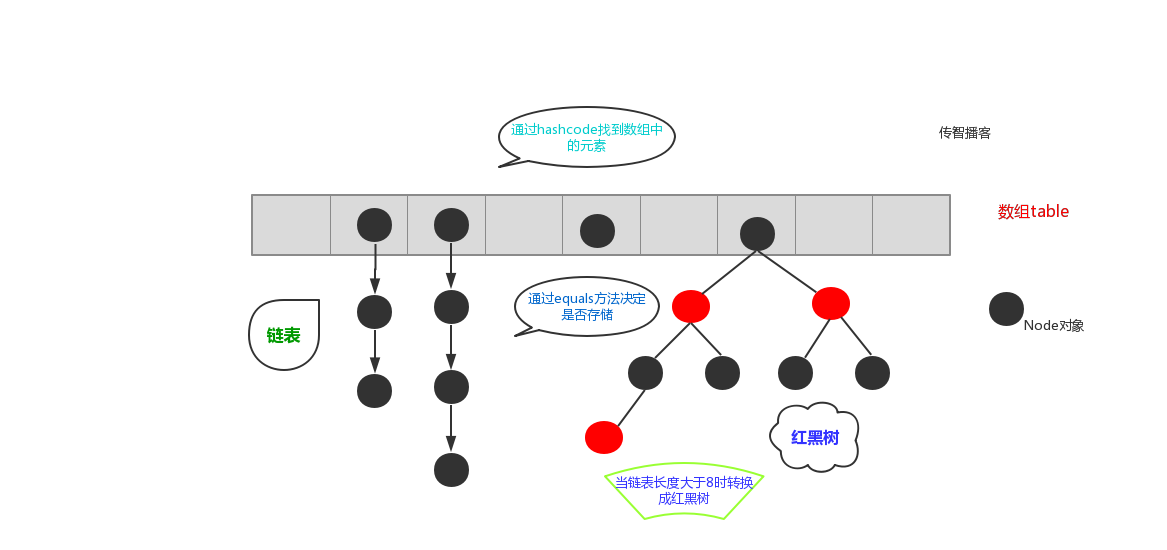
2、存储的流程
三、HashMap数据结构
1、hash表数据结构
1)简介
哈希表是一个通过数组和链表相结合而成的数据结构,既避免了数组的增删慢,也避免了链表查询查询慢的的缺陷。
数组 :
数组的存储区是连续的,占用内存严重,故空间复杂度很大。但数组的二分查找时间度小;数组的特点:寻址容易,插入和删除困难。
链表 :
链表的储存区离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度大;
链表的特点:寻址困难,插入和删除容易。
2)保证数据唯一的原理
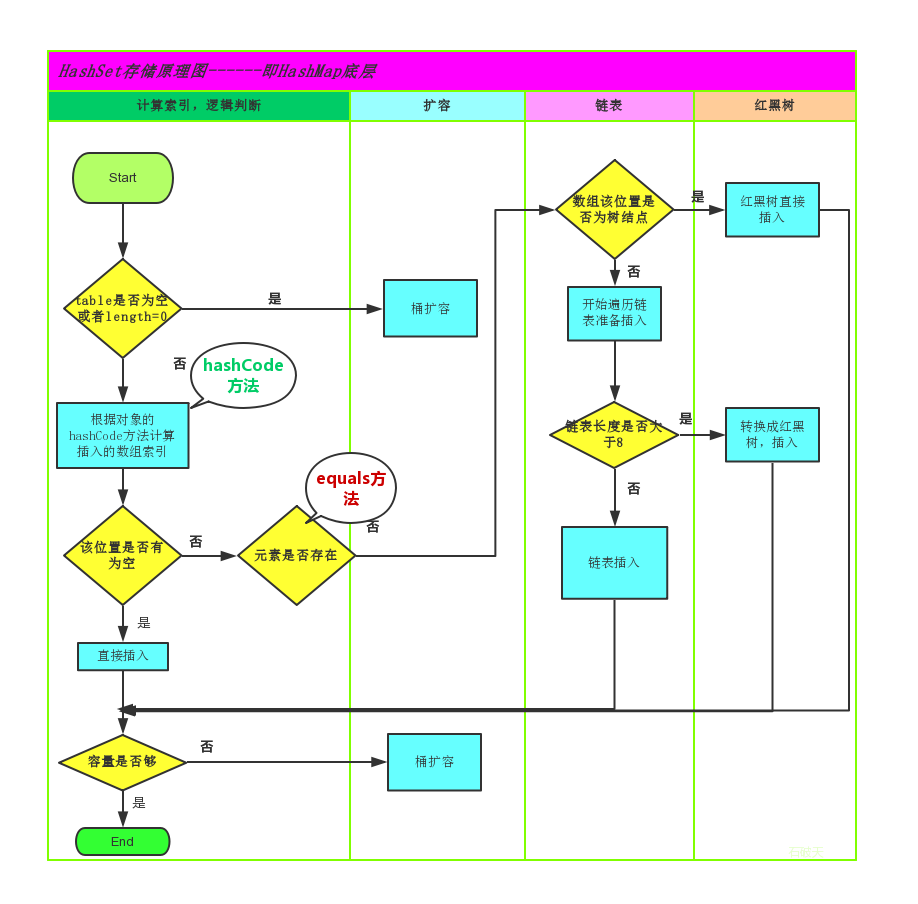
当HashMap集合存储元素的时候,就会调用该元素的hashCode0方法计算哈希值
判断该哈希值对应的位置上是否有相同哈希值的元素
如果该位置上没有相同哈希值的元素,就直接存储
如果该位置上有相同哈希值的元素,就说明产生了哈希冲突
产生了哈希冲实,就得调用该元素的equals方法,与该哈希值位置上的所有元素进行-比较
如果比较完后,没有一个元素与该元素相同,就直接存储
如果比较完后,只要有任意一个元素与该元素相同,就不存储

3、红黑树的数据结构
1)简介
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构,它是在1972年由Rudolf Bayer发明的,当时被称之为平衡二叉B树,后来,在1978年被Leoj.Guibas和Robert Sedgewick修改为如今的”红黑树”。它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,可以是红或者黑;
红黑树不是高度平衡的,它的平衡是通过”红黑树的特性”进行实现的;
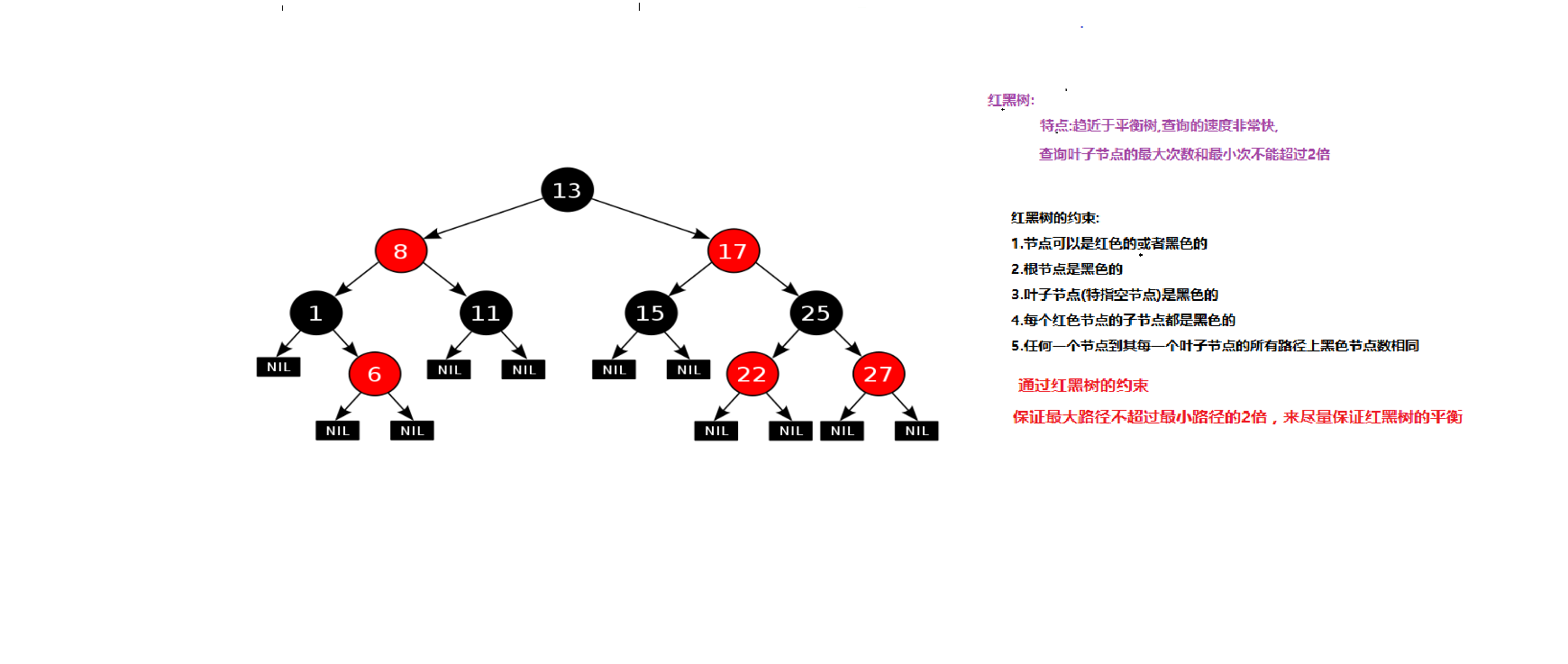
2)红黑树特性
每一个节点或是红色的,或者是黑色的。
根节点必须是黑色
每个叶节点(Nil)是黑色的;(如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点)
如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点;
在进行元素插入的时候,和之前一样; 每一次插入完毕以后,使用黑色规则进行校验,如果不满足红黑规则,就需要通过变色,左旋和右旋来调整树,使其满足红黑规则;
3)与AVL树的区别
1、红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
2、平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
四、算法
1、负载因子(load factor)
如果一个hash表中桶的个数为 size , 存储的元素个数为used .则我们称 used / size 为负载因子loadFactor . 一般的情况下,当loadFactor<=1时,hash表查找的期望复杂度为O(1). 因此。每次往hash表中加入元素时。我们必须保证是在loadFactor <1的情况下,才可以加入。
2、初始容量与扩容
HashMap的初始容量为16,Hashtable初始容量为11,两者的负载填充因子默认都是0.75。
如果size大小到达阈值,则扩容一倍,依旧为2的整次幂
最大容量:因为计算采用int值,int值最大为2的31次-1,达不到2的31次,所以为2的30次。
3、扩容的实现
当我们加入一个新元素时。一旦loadFactor大于等于1了,我们不能单纯的往hash表里边加入元素。
由于加入完之后,loadFactor将大于1,这样也就不能保证查找的期望时间复杂度为常数级了。这时。我们应该对桶数组进行一次容量扩张,让size增大 。
这样就能保证加入元素后 used / size 仍然小于等于1 , 从而保证查找的期望时间复杂度为O(1).可是。怎样进行容量扩张呢? C++中的vector的容量扩张是一种好方法。
于是有了例如以下思路 : Hash表中每次发现loadFactor==1时,就开辟一个原来桶数组的两倍空间(称为新桶数组),然后把原来的桶数组中元素所有转移过来到新的桶数组中。注意这里转移是须要元素一个个又一次哈希到新桶中的。原因后面会讲到。
这样的方法的缺点是,容量扩张是一次完毕的,期间要花非常长时间一次转移hash表中的全部元素。这样在hash表中loadFactor==1时。往里边插入一个元素将会等候非常长的时间。
4、Redis中的实现
Redis 是一个高效的 key-value 缓存系统,也可以理解为基于键值对的数据库。
Redis也是采取链地址法解决哈希冲突。
我们知道,Java发生扩容的瞬间,是需要先将原哈希表中所有键值对都转移到新的哈希表中,这个过程是比较慢的,此时插入该元素的性能相当低。
而Redis对于这一部分,采取的是分摊转移的方式。即当插入一个新元素x触发了扩容时,先转移第一个不为空的桶到新的哈希表,然后将该元素插入。而下一次再次插入时,继续转移旧哈希表中第一个不为空的桶,再插入元素。直至旧哈希表为空为止。这样一来,理想情况下,插入的时间复杂度是O(1)。
在Redis的实现中,新插入的键值对会放在箱子中链表的头部,而不是在尾部继续插入。
这种方案是基于两点考虑:
一是由于找到链表尾部的时间复杂度为O(n),且需要额外的内存地址来保存链表的尾部位置,而头插法的时间复杂度为O(1)。
二是处于Redis的实际应用场景来考虑。对于一个数据库系统来说,最新插入的数据往往更可能频繁地被获取,所以这样也能节省查找的耗时
五、ConcurrentHashMap、HashTable、HashMap区别
1、HashMap
因为多线程环境下,使用Hashmap进行put操作可能会引起死锁,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。【PS:HashMap 是允许key值为空的】
2、HashTable
Hashtable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下Hashtable的效率非常低下。因为当一个线程访问Hashtable的同步方法时,其他线程访问Hashtable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
3、ConcurrentHashMap
1)jdk7版本
ConcurrentHashMap和HashMap设计思路差不多,但是为支持并发操作,做了一定的改进,ConcurrentHashMap引入Segment 的概念,目的是将map拆分成多个Segment(默认16个)。操作ConcurrentHashMap细化到操作某一个Segment。在多线程环境下,不同线程操作不同的Segment,他们互不影响,这便可实现并发操作。
2)jdk8版本
jdk8版本的ConcurrentHashMap相对于jdk7版本,发送了很大改动,jdk8直接抛弃了Segment的设计,采用了 较为轻捷的Node + CAS + Synchronized设计,保证线程安全。
3)总结
1、get方法不加锁;
2、put、remove方法要使用锁
jdk7使用锁分离机制(Segment分段加锁)
jdk8使用cas + synchronized 实现锁操作
3、Iterator对象的使用,运行一边更新,一遍遍历(可以根据原理自己拓展)
4、复合操作,无法保证线程安全,需要额外加锁保证
5、并发环境下,ConcurrentHashMap 效率较Collections.synchronizedMap()更高